Preprocessing
Parameter Overview
The table below lists the options of the executed module.
| Option |
Value |
| filtering.whitelist |
|
| filtering.blacklist |
|
| filtering.snp |
yes |
| filtering.greedycut |
no |
| filtering.coverage.threshold |
5 |
| filtering.greedycut.rc.ties |
row |
| imputation.method |
none |
| filtering.high.coverage.outliers |
yes |
| filtering.low.coverage.masking |
yes |
| normalization.method |
swan |
| normalization.background.method |
methylumi.noob |
| normalization.plot.shifts |
yes |
| filtering.context.removal |
CC, CAG, CAH, CTG, CTH, Other |
| filtering.missing.value.quantile |
0.5 |
| filtering.sex.chromosomes.removal |
yes |
| filtering.deviation.threshold |
0 |
| distribution.subsample |
1000000 |
Removal of SNP-enriched Sites
SNP-based filtering was not performed because the site annotation does not include SNP information.
Removal of High Coverage Outlier Sites
502 sites were detected as high coverage outlier in at least one sample and removed at this step. An outlier site is defined as one whose coverage exceeds 50 times the 0.95-quantile of coverage values in its sample. The list of removed sites is available in a dedicated table accompanying this report.
Masking of Sites with Low Coverage
A total of 7070752 sites with coverage less than 5 were masked by NA in the methylation table The numbers of masked sites per sample are available in a dedicated table accompanying this report.
Removal of Sites on Sex Chromosomes
87560 sites on sex chromosomes were removed at this step. The list of removed sites is available in a dedicated table accompanying this report.
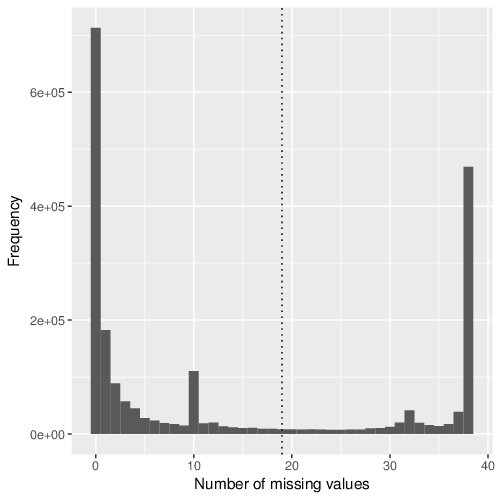
Removal of Sites with (Many) Missing Values
704163 sites were removed because they contain more than 19 missing values in the methylation table. This threshold corresponds to 50% of all samples. The total number of missing values in the methylation table before this filtering step was 30059692. A dedicated table of all removed sites is attached to this report.
The figure below shows the distribution of missing values per site.
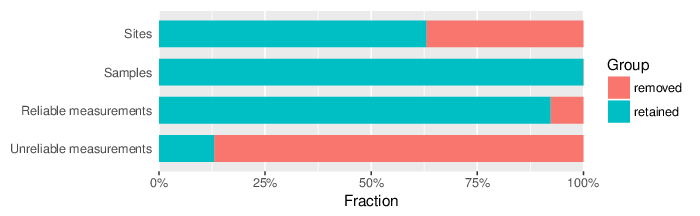
Filtering Summary
As a final outcome of the filtering procedures, 792225 sites and 0 samples were removed (38 samples and 1353082 sites were retained). These statistics are presented in a dedicated table that accompanies this report and visualized in the figure below.
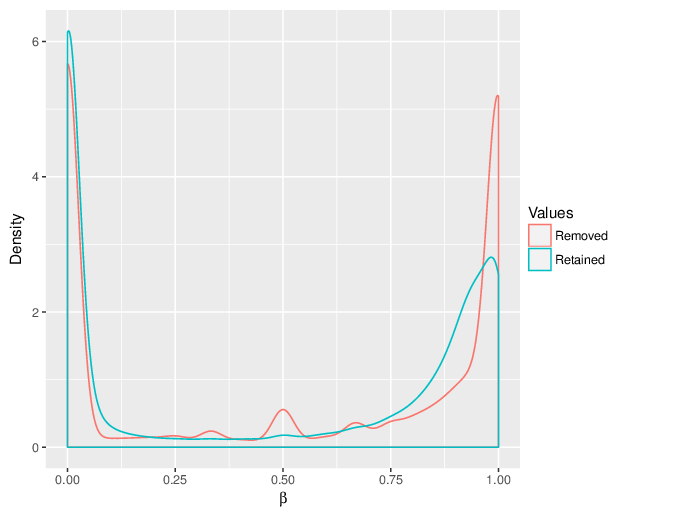
The figure below compares the distributions of the removed methylation β values and of the retained ones.
This report was generated on 2017-12-22 by
RnBeads version 1.11.3.